


When I presented "intro to the semantic web" slides in TopQuadrant product training classes, I described how people talking about "semantics" in the context of semantic web technology mean something specific, but that other claims for computerized semantics (especially, in many cases, "semantic search") were often vague attempts to use the word as a marketing term. Since joining CCRi, though, I've learned plenty about machine learning applications that use semantics to get real work done (often, "semantic search"), and they can do some great things.
Semantic Web semantics
To review the semantic web sense of "semantics": RDF gives us a way to state facts using {subject, predicate, object} triples. RDFS and OWL give us vocabularies to describe the resources referenced in these triples, and the descriptions can record semantics about those resources that let us get more out of the data. Of course, the descriptions themselves are triples, letting us say things like {ex:Employee rdfs:subClassOf ex:Person}, which tells us that any instance of the ex:Employee class is also an instance of ex:Person.
That example indicates some of the semantics of what it means to be an employee, but people familiar with object-oriented development take that ability for granted. OWL can take the recording of semantics well beyond that. For example, because properties themselves are resources, when I say {dm:locatedIn rdf:type owl:TransitiveProperty}, I'm encoding some of the meaning of the dm:locatedIn property in a machine-readable way: I'm saying that it's transitive, so that if {x:resource1 dm:locatedIn x:resource2} and {x:resource2 dm:locatedIn x:resource3}, we can infer that {x:resource1 dm:locatedIn x:resource3}.
A tool that understands what owl:TransitiveProperty means will let me get more out of my data. My blog entry Trying Out Blazegraph from earlier this year showed how I took advantage of OWL metadata to query for all the furniture in a particular building even though the dataset had no explicit data about any resources being furniture or any resources being in that building other than some rooms.
This is all built on very explicit semantics: we use triples to say things about resources so that people and applications can understand and do more with those resources. The interesting semantics work in the machine learning world is more about inferring semantic relationships.
Semantics and embedded vector spaces
(All suggestions for corrections to this section are welcome.) Machine learning is essentially the use of data-driven algorithms that perform better as they have more data to work with, "learning" from this additional data. For example, Netflix can make better recommendations to you now than they could ten years ago because the additional accumulated data about what you like to watch and what other people with similar tastes have also watched gives Netflix more to go on when making these recommendations.
The world of distributional semantics shows that analysis of what words appear with what other words, in what order, can tell us a lot about these words and their relationships—if you analyze enough text. Let's say we begin by using a neural network to assign a vector of numbers to each word. This creates a collection of vectors known as a "vector space"; adding vectors to this space is known as "embedding" them. Performing linear algebra on these vectors can provide insight about the relationships between the words that the vectors represent. In the most popular example, the mathematical relationship between the vectors for the words "king" and "queen" is very similar to the relationship between the vectors for "man" and "woman". This diagram from the TensorFlow tutorial Vector Representations of Words shows that other identified relationships include grammatical and geographical ones:
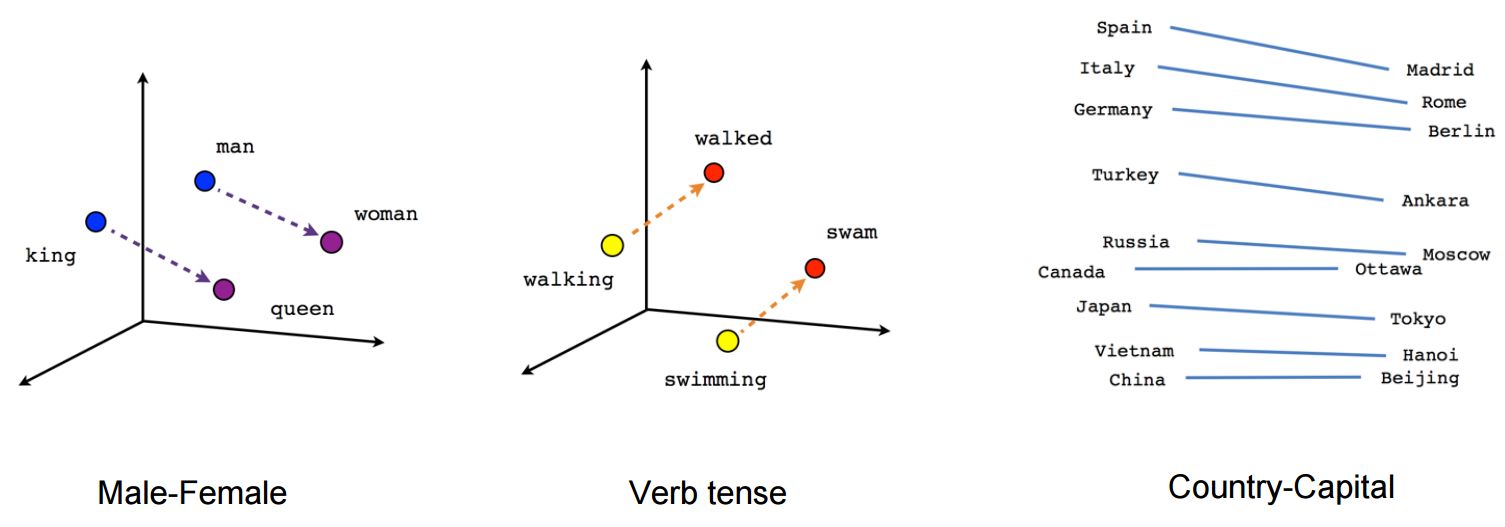
The popular open source word2vec implementation of this developed at Google includes a script that lets you do analogy queries. (The TensorFlow tutorial mentioned above uses word2vec; another great way to get hands-on experience with word vectors is Radim Rehurek's gensim tutorial.) I installed word2vec on an Ubuntu machine easily enough, started up the demo-analogy.sh script, and it prompted me to enter three words. I entered "king queen father" to ask it "king is to queen as father is to what?" It gave me a list of 40 word-score pairs with these at the top:
mother 0.698822
husband 0.553576
sister 0.552917
her 0.548955
grandmother 0.529910
wife 0.526212
parents 0.512507
daughter 0.509455
Entering "london england berlin" produced a list that began with this:
germany 0.522487
prussia 0.482481
austria 0.447184
saxony 0.435668
bohemia 0.429096
westphalia 0.407746
italy 0.406134
I entered "run ran walk" in the hope of seeing "walked" but got a list that began like this:
hooray 0.446358
rides 0.445045
ninotchka 0.444158
searchers 0.442369
destry 0.435961
It did a pretty good job with most of these, but obviously not a great job throughout. The past tense of walk is definitely not "hooray", but these inferences were based on a training data set of 96 megabytes, which isn't very large. A Google search on phrases from the text8 input file included with word2vec for this demo shows that it's probably part of a 2006 Wikipedia dump used for text compression tests and other processes that need a non-trivial text collection. More serious applications of word2vec often read much larger Wikipedia subsets as training data, and of course you're not limited to using Wikipedia data: the exploration of other datasets that use a variety of spoken languages and scripts is one of the most interesting aspects of these early days of the use of this technology.
The one-to-one relationships shown in the TensorFlow diagrams above make the inferred relationships look more magical than they are. As you can see from the results of my queries, word2vec finds the words that are closest to what you asked for and lists them with their scores, and you may have several with good scores or none. Your application can just pick the result with the highest score, but you might want to first set an acceptable cutoff value so that you don't take the "hooray" inference too seriously.
On the other hand, if you just pick the single result with the highest score, you might miss some good inferences, because while Berlin is the capital of Germany, it was also the capital of Prussia for over 200 years, so I was happy to see that get the second-highest score there—although, if we put too much faith in a score of 0.482481 (or even of 0.522487) we're going to get some "king queen father" answers that we don't want. Again, a bigger training data set would help there.
If you look at the demo-analogy.sh script itself, you'll see various parameters that you can tweak when creating the vector data. The use of larger training sets is not the only thing that can improve the results above, and machine learning expertise means not only getting to know the algorithms that are available but also learning how to tune parameters like these.
The script is simple enough that I saw that I could easily revise it to make it read some other file instead of the text8 one included with it. I set it to read the Summa Theologica, in which St. Thomas Aquinas laid out all the theology of the Catholic Church, as I made grand plans for Big Question analogy queries like "man is to soul as God is to what?" My eventual query results were a lot more like the "run ran walk hooray" results above than anything sensible, with low scores for what it did find. With my text file of the complete Summa Thelogica weighing in at 17 megabytes, I was clearly hoping for too much from it. I do have ideas for other input to try and I encourage you to try it for yourself.
An especially exciting thing about the use of embedding vectors to identify potentially previously unknown relationships is that it's not limited to use on text. You can use it with images, video, audio, and any other machine readable data, and at CCRi, we have. (I'm using the marketing "we" here; if you've read this far you're familiar with all of my hands-on experience with embedding vectors.)
Embedding vector space semantics and semantic web semantics
Can there be any connection between these two "semantic" technologies? RDF-based models are designed to take advantage of explicit semantics, and a program like word2vec can infer semantic relationships and make them explicit. Modifications to the scripts included with word2vec could output OWL or SKOS triples that enumerate relationships between identified resources, making a nice contribution to the many systems using SKOS taxonomies and thesauruses. Another possibility is that if you can train a machine learning model with instances (for example, labeled pictures of dogs and cats) that are identified with declared classes in an ontology, then running the model on new data can do classifications that take advantage of the ontology—for example, after identifying new cat and dog pictures, a query for mammals can find them.
Going the other way, machine learning systems designed around unstructured text can often do even more with structured text, where it's easier to find what you want, and I've learned at CCRi that RDF (if not RDFS or OWL) is much more popular among such applications than I realized. Large taxonomies such as those of the Library of Congress, DBpedia, and Wikidata have lots of synonyms, explicit subclass relationships, and sometimes even definitions, and they can contribute a great deal to these applications.
A well-known success story in combining the two technologies is IBM's Watson. The paper Semantic Technologies in IBM Watson describes the technologies used in Watson and how these technologies formed the basis of a seminar course given at Columbia University; distributional semantics, semantic web technology, and DBpedia all play a role. Frederick Giasson and Mike Bergman's Cognonto also looks like an interesting project to connect machine learning to large collections of triples. I'm sure that other interesting combinations are happening around the world, especially considering the amount of open source software available in both areas.
Please add any comments to this Google+ post.