

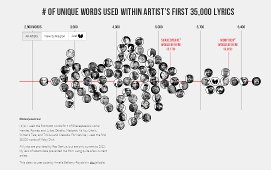
About a month ago, media outlets ranging from NPR to Rolling Stone to Britain's Daily Mail reported on how a "designer, coder, and data scientist" named Matt Daniels had analyzed the number of unique words in samples of work by Shakespeare, Herman Melville, and 85 rappers. He then published a chart and article about how their scores related to each other. The highest score went to Aesop Rock, who I thought I'd heard of but hadn't—I was confusing him with A$AP Rocky, who was not included in the survey.
The chart and discussion were interesting, but what I really wanted to see was the complete list of subjects with their scores, and after searching around the web a bit I found that it was under my nose the whole time—the chart is dynamically generated from JSON embedded in his web page. So, I converted that JSON to RDF, used some SPARQL to retrieve additional data about each rapper from DBpedia such as their record labels, the years their careers began, any subject keywords assigned to them, and the abstracts, or summaries of their careers. (You'll find more details on the procedure for doing this below; the resulting integrated data is available for you to query here as a Turtle file.) Combining this additional data with the vocabulary scores let me do some interesting queries and provide an excellent example of how RDF and SPARQL let you perform ad hoc data integration to combine different data sets into aggregates that let you identify new patterns and other information.
For example, of all record labels with more than four rappers associated with them, I found that MCA's roster had the highest average vocabulary score at 5472.5, well above the overall average of 4624. Who are these artists? Another simple query showed their names and scores:
| GZA | 6426 |
| The Roots | 5803 |
| Killah Priest | 5737 |
| Blackalicious | 5480 |
| Big Daddy Kane | 4768 |
| Rakim | 4621 |
(As Daniels pointed out, members of the Wu-Tang Clan tend to have higher scores, so GZA and Killah Priest are a big help to MCA's average score.)
The dcterms:subject values assigned to the rappers in DBpedia provide the most interesting opportunities for exploration. In fact, it turned out that I didn't even need to pull down the record label values, because they each have corresponding dcterms:subject values. For example, each of the artists listed above have a dcterms:subject value of http://dbpedia.org/resource/Category:MCA_Records_artists along with their other dcterms:subject values.
Of the subject categories with more than four rappers, here are several interesting ones with high average scores, ranked by number of members in the category:
| count | avg score | |
|---|---|---|
| Members of the Nation of Gods and Earths | 13 | 5117 |
| Underground rappers | 8 | 5849 |
| People from Brooklyn | 7 | 5323 |
| MCA Records artists | 7 | 5401 |
| Rappers from Long Island | 6 | 5160 |
| Alternative hip hop groups | 5 | 5286 |
| Wu-Tang Clan members | 5 | 5611 |
I hadn't heard of the Nation of Gods and Earths, also known as the Five-Percent Nation; again, we have Wu-Tang skewing the numbers up. After I saw the high averages for "People from Brooklyn" and "Rappers from Long Island" but no mention of Staten Island, I clicked around and found out that only about half of Wu-Tang came from the borough in which they were based, which I never knew before.
Here are some interesting low scoring categories. Again, remember that the overall average score is 4624:
| count | avg score | |
|---|---|---|
| Participants in American reality television series | 8 | 4108 |
| People convicted of drug offenses | 7 | 3741 |
| American philanthropists | 6 | 4022 |
| American shooting survivors | 5 | 4025 |
| American fashion businesspeople | 5 | 4110 |
Of course, the data collection itself isn't very scientific; what constitutes an "alternative" rapper? A less successful artist popular with music nerds? "People convicted of drug offenses" seems like a more cut and dried category, but remember that data from a Wikipedia page is not an authoritative source for such facts.
As with the list of MCA artists above, a simple query of the data can tell you who falls in each of these categories, so pull down the data from the link above and have fun querying it. If you're interested in how I did the integration, read on.
Integrating the data
Upon seeing that Daniels includes a score for Ghostface Killah, it's easy to ask DBpedia for all the { <http://dbpedia.org/resource/Ghostface_Killah> ?p ?o } triples. It's not as simple for many other artists, though, for several reasons:
Some rappers use stage names that are common phrases and words, so putting that name at the end of "http://dbpedia.org/resource/" won't necessarily get you data about them.
Tricky spellings and punctuation are pretty common in hiphop names. For example, Jay Z originally spelled his name with a hyphen but later dropped it, much as LexisNexis did twelve years earlier.
Daniels sometimes included qualifications in names ("GZA (only solo albums)"), included or didn't include the word "The" that was in the DBpedia name ("Roots" vs. "The Roots") or just spelled their names wrong, such as omitting the final "t" from "Missy Elliott."
Dropping parenthesized qualifications was easy enough. Even better, DBpedia often has the data necessary to find the page based on a slightly wrong name, and the techniques I described in Normalizing company names with SPARQL and DBpedia worked for most of them. This is not a minor point: even when the names aren't quite right, sending the right SPARQL queries to DBpedia can still retrieve valuable data about them. This has applications in all kinds of domains.
You can find the scripts and queries mentioned below in rapperrdf.zip. The rapperdata.js file is taken directly from the source of Daniels' web page, and loads his data into an array. Another JavaScript file, rappervocab.js, loads rapperdata.js and outputs Turtle RDF of the rapper's scores and the Daniels versions of their names. (If you're using the TopBraid platform and working with JSON, there's an excellent SPARQLMotion module to automate the conversion of any JSON to RDF.) I used Rhino to run the JavaScript, as I described in Javascript from the command line.
Another short script called rapperValuesList.js reads the same data and creates the list of names that I inserted as a VALUES list into the retrieveRapperData.rq SPARQL query that actually retrieves the relevant data from DBpedia. (VALUES is a great SPARQL technique for saying "I need data about this list of specific things," as I've written here before.) This SPARQL query uses the SERVICE keyword to send the request off to DBpedia and does a CONSTRUCT to save the triples. It uses the "Normalizing company names" trick mentioned above to see if the Daniels name with the parenthesized part stripped out is either the "official" rdfs:label value for a resource or otherwise attached to something that gets redirected to that.
Of the 81 artists in Daniels' list, there were 12 whose names couldn't be looked up even with the redirect trick in retrieveRapperData.rq. To account for these, I created extraRapperDanielsNames.ttl with a text editor to link Daniels' names for these 12 extra rappers to their DBpedia resource URIs such as http://dbpedia.org/resource/Common_(entertainer), which I had to look up manually. The retrieveExtraRapperData.rq query then uses that to retrieve the same data about those 12.
The queries only retrieve the start year, record label, abstract, and subjects about the artists because they all had those values. Retrieving data that only some of them have (such as the birth year, which you don't have for bands like The Roots) would mean using the OPTIONAL keyword, and DBpedia said that my query would take too long when I tried that—I'm sure the big VALUES part has a lot to do with that.
The integrateRapperData.rq query reads the extraRapperDanielsNames.ttl data and the data created by rappervocab.js, retrieveRapperData.rq, and retrieveExtraRapperData.rq, and then creates the final product: rapperDataIntegrated.ttl.
Querying the data
Next was the fun part: executing queries to explore that integrated data. The zip file includes queries to find the following information from rapperDataIntegrated.ttl:
| averageScore.rq | overall average Daniels score |
| averageScoreByLabel.rq | average score by record label for labels with more than four artists associated with them |
| subjectReport.rq | average score by subject associated with the rappers for all subjects (like "Underground rappers" and "American philanthropists") |
| MCAArtists.rq | MCA artists |
| JamaicanDescent.rq | the name, Daniels score, and abstract of "American rappers of Jamaican descent" |
That last one can provide a template for the creation of other queries about who falls into which subject categories.
Linking this data with other data about the artists from some of the blue parts of the Linked Data Cloud such as DBTune or the BBC would provide some even more interesting possibilities. As one taste, this link has a SPARQL query that retrieves all the MusicBrainz data about Missy Elliott.
Please add any comments to this Google+ post.