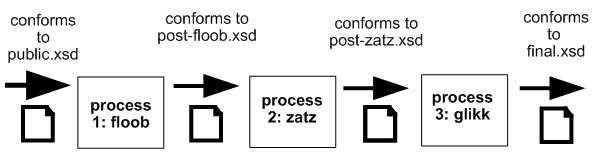
A document's relationship to related schemas as it moves through a sample processing pipeline
Bob DuCharme 12/02
The whole idea of sending a stream of XML documents through a pipeline
instead of through a monolithic process that performs all necessary processing
is getting more popular lately, as shown by projects such as XPipe and
But, how can I maintain a set of related schemas used for different stages in the processing of the same document set? For example:
A document received from outside of the system must pass through three processes which we'll call floob, zatz, and glikk. At each stage, the document conforms to a slightly different schema. These schemas are important, because they serve as a contract between the implementers of each process; the zatz developers use the post-floob.xsd schema as part of their requirements that specify input, and the glikk designers do the same with post-zatz.xsd. (Before you read too much into the file extensions, note that the problem and solution are the same for both W3C Schemas an RELAX NG. I'll use W3C Schemas in describing my problem and solution and then say a word about how I tested it with RELAX NG.)
A document's relationship to related schemas as it moves through a sample processing pipeline
These are not different schemas. They're variations on the same schema. The problem is how to track the variations. The first two options that come to mind are these:
Have one schema, and set everything that doesn't appear in all stages to be optional.
Store all the stage schemas separately and edit the appropriate ones when necessary.
In a complex enough environment, the first option is unacceptable. If the floob process adds a checkIn attribute value to a document and the zatz process needs to use that value, then the checkIn attribute must be a mandatory attribute in the post-floob.xsd schema, but it can't be in the public.xsd schema.
Anyone who came to XML from an electronic publishing background knows that the second option is also unacceptable, because it's too prone to error. As with the documents themselves, the best way to create multiple related ones reliably and repeatably is to create a master one and generate the others from it.
This paper describes an approach to doing just that: creating a schema that stores information about which components go into which schemas and extracting the various stage schemas as necessary.
First, a note on terminology: I decided to call the schemas "stage schemas," because each one is the schema for documents at a different stage of processing. I avoided the term "versions," which implies the use of schemas released at different points in time to each replace the preceding version.
Below is the beginning of the master schema from which the XSLT stylesheet generates schemas for the individual stages. (all files mentioned are available at http://www.snee.com/xml/schemaStages.zip) Non-standard parts of the schema from the http://www.snee.com/ns/stages namespace are bolded.
There are two kinds of additions:
An sn:stages element inside of an xs:appinfo element to list the names assigned to the various stages
An sn:stages attribute added to some schema components to identify which stages use those components. Any schema components without this attribute, such as the element declaration for the title element, are assumed to be meant for all the stages.
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:sn="http://www.snee.com/ns/schemas">
<xs:element name="article">
<xs:annotation>
<xs:appinfo>
<sn:stages>
<sn:stage name="public"/>
<sn:stage name="post-floob"/>
<sn:stage name="post-zatz"/>
<sn:stage name="final"/>
</sn:stages>
</xs:appinfo>
</xs:annotation>
<xs:complexType>
<xs:sequence>
<xs:element ref="title" maxOccurs="1"/>
<xs:element ref="par" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="dateline" type="xs:string" use="required"
sn:stages="post-zatz final"/>
<xs:attributeGroup ref="stamps"
sn:stages="post-floob post-zatz final"/>
</xs:complexType>
</xs:element>
<xs:element name="title" type="xs:string"/>
<!-- schema continued; see complete master.xsd file in zip file -->
The elements and attribute don't have to be from the http://www.snee.com/ns/schemas namespace. As long as they're not from http://www.w3.org/2001/XMLSchema namespace, schema processing software is supposed to ignore them. Besides, this master schema isn't for use with documents, anyway; its purpose is to provide a base from which to generate the various production schemas.
A short, straightforward XSLT stylesheet named getStage.xsl stylesheet takes a parameter that names the schema stage to extract and creates a schema for that stage from the source schema. For example, if the master schema is stored in master.xsd and you want to pull a post-floob one and store it in post-floob.xsd, enter the following command line to apply the stylesheet to master.xsd using the Saxon XSLT processor:
saxon master.xsd getstage.xsl stageName=post-floob > post-floob.xsd
I found it easier to create a batch file called getStage.bat that could be run with a simpler command line, like this:
getStage post-floob xsd
(The xsd parameter shows that it's being run with W3C Schemas.) Before extracting a schema for the designated stage, getStage.xsl checks whether the supplied stage name (in this case, "post-floob") is declared as one of the stages for that master schema—that is, whether it's the value of a name attribute in an sn:stage child of the sn:stages element—and outputs an error message and aborts if not.
The stylesheet is short and simple. It first declares a stageName parameter so that the process running the stylesheet can pass the name of the desired stage into the stylesheet for use in its processing. The stylesheet then has four templates:
One suppresses the elements from the http://www.snee.com/ns/schemas namespace. They do their job by contributing to the extraction process, and will play no role in the extracted schemas.
One copies attributes, comments, and processing instructions unchanged.
One processes the document root. It performs a few startup checks, such as making sure that the desired stage name is one that the master schema knows about, and then passes the contents along unchanged.
The most important template rule processes the elements of the stylesheet. This one is also pretty short: if an element doesn't have the sn:stages attribute, it gets copied to the result tree with no changes; if the element does have this attribute, its contents get copied to the result tree only if the name of the schema stage to extract is included in the list of stages stored in that attribute value.
The stylesheet also declares a key using the stage names declared in the sn:stages element so that they can be looked up more quickly.
An earlier version of the stylesheet used the tokenize() function to split up the space-delimited lists of stage names in the sn:stages attributes. While not part of the XSLT 1.0 Recommendation, this function, or some variation on it, is available with nearly every XSLT processor. Nevertheless, because it's not part of latest Recommendation, I changed the part that compares the name of the stage to extract with each space-delimited sn:stages attribute value string so that it uses XSLT and XPath 1.0 string and space manipulation functions instead of relying on an extension.
Comments in the getStage.xsl file include further details on how it works. Although various XSLT tricks are used to make processing more efficient, it's simple enough that it could be implemented using any XML processing system such as a SAX or DOM.
To test the system, I wrote a test.bat batch file that calls the getStage.bat batch file four times to extract each of the four stages declared in master.xsd into their own schemas. It then calls the Xerces Java parser to validate sample documents against those schemas to make sure that the documents match up to the extracted schemas.
I first worked this out with schemas based on the W3C Schema Recommendation. When I decided to try it with RELAX NG schema, I didn't have to change a byte of the getStage.xsl stylesheet; it worked just fine as it was. All I had to do was to change the getStage.bat driver file to allow for the possibility of reading from and outputting to files with an extension of rng.
To test it with RELAX NG schemas, I used Sun's free rngconv utility (http://wwws.sun.com/software/xml/developers/relaxngconverter/) to convert master.xsd to master.rng. Then, I added the declarations for the xsi:noNamespaceSchemaLocation attribute and namespace so that I could use the same XML documents (public.xml, post-floob.xml, and so forth) as a test, and I added the snee stage elements and attribute described above to the RELAX NG schema. After making my modifications to the getStage.bat driver file to allow for the possibility of rng extensions, I used it to create RELAX NG schemas from master.rng for the four stages. Sun's multi-schema validator (http://wwws.sun.com/software/xml/developers/multischema/) showed that the same test documents were as valid against the extracted RELAX NG schemas as Xerces found those documents to be against the W3C stage schemas extracted from master.xsd. (The test.bat file includes lines to perform these RELAX NG extractions and tests.)
The example that I made up to test this was quite simple; download http://www.snee.com/xml/schemaStages.zip for the stylesheet, the master schemas, the batch file, the eight extracted schemas, and four sample document files that conform to each W3C/RNG pair of schemas. The test.bat file does all the extractions and schema validations of the sample documents against the various extracted schemas.
This is all still at the prototype stage, but it's all simple enough to have a good chance of scaling well. Schema complexity is a problem that many will have to deal with, and there will be two classes of solutions: proprietary ones and open—most likely XML-based—ones. Legally adding two element types and one attribute to a schema and then processing it for different needs with a short stylesheet has a lot of appeal, especially when the same process and stylesheet works with both W3C Schemas and Relax NG schemas.